DMBI END TERM EXAM 2018 WITH SOLUTIONS
END TERM EXAM - Data Mining and Business Intelligence (2018)
Q1 Answer all the following questions in brief:-
(a) What is Data warehouse? Discuss its characteristics.
(a) A data warehouse is a large, centralized repository that stores data from various sources in a structured format designed to facilitate business intelligence (BI) and decision-making. Its characteristics include subject orientation, integration, time variance, non-volatile storage, and summarized data.
(b) What are the basic difference between OLAP and Data mining?
(b) OLAP (Online Analytical Processing) and data mining are both techniques used for data analysis, but OLAP is used to analyze historical data in a multi-dimensional format, whereas data mining is used to discover hidden patterns and relationships in large datasets.
(c) What is Dimensional modeling and how it is different from the E-R Model?
(c) Dimensional modeling is a technique used to design data warehouses that organizes data into dimensions and measures, making it easy to analyze large datasets. It is different from the E-R (Entity-Relationship) model in that it focuses on the analytical needs of a data warehouse, while the E-R model focuses on transaction processing.
(d) What is data granularity in Data Warehouse?
(d) Data granularity in a data warehouse refers to the level of detail of the data being stored. This can range from highly summarized data to highly detailed data.
e) What is Data Mart? Differentiate between dependent and independent Data marts?
(e) A data mart is a subset of a data warehouse that is designed to serve the needs of a specific business unit or department. Dependent data marts rely on the central data warehouse for their data, while independent data marts have their own data sources.
(f) How decision tress assist in the process of data mining?
(f) Decision trees are a type of data mining technique that uses a tree-like model to visualize and analyze data. They assist in the process of data mining by identifying patterns and relationships within the data that can be used to make decisions.
(g) Give two major differences between STAR schema and Snowflake schema?
(g) The two major differences between a STAR schema and a Snowflake schema are that a STAR schema has denormalized dimensions while a Snowflake schema has normalized dimensions, and a STAR schema has fewer tables and joins than a Snowflake schema.
(h) Differentiate between drill down, rollup and slice and dice operations?
(h) Drill down, rollup, and slice and dice are operations used in OLAP to analyze data. Drill down is the process of going from a higher-level summary to a lower-level detail, rollup is the process of going from a lower-level detail to a higher-level summary, and slice and dice is the process of viewing data from different perspectives.
(i) Explain the benefits of OLAP?
(i) The benefits of OLAP include fast query response time, the ability to analyze large amounts of data quickly, support for complex calculations, and the ability to view data from multiple perspectives.
(j) What are the characteristics of strategic information?
(j) The characteristics of strategic information include its relevance to long-term decision-making, its ability to provide a comprehensive view of the organization, and its focus on critical success factors and key performance indicators. It is often used by top-level executives to make strategic decisions that impact the organization as a whole.
Q2 State all the guidelines of Dr. Codd's for a DBMS system giving brief description about each? (12.5 Marks Question)
(b) Explain Dimension Table in wide, the fact table is Deep. What is Fact less Fact Table? (6)

Dr. E.F. Codd, the father of the relational database, proposed twelve rules for relational database management systems (RDBMS) in 1985. These rules, commonly known as Codd's 12 rules, are intended to define what is required of a true relational database management system. Below is a brief description of each of the 12 rules:
Information Rule: All information in a relational database is to be represented explicitly at the logical level and in exactly one way.
Guaranteed Access Rule: Each and every datum (atomic value) in a relational database is to be logically accessible by resorting to a combination of table name, primary key value and column name.
Systematic Treatment of Null Values: Null values (distinct from empty character string or a string of blank characters and distinct from zero or any other number) are supported in a fully relational DBMS for representing missing information and inapplicable information in a systematic way, independent of data type.
Active Online Catalog: The database description is represented at the logical level in the same way as ordinary data, so authorized users can apply the same relational language to its interrogation as they apply to the regular data.
Comprehensive Data Sublanguage Rule: A relational system may support several languages and various modes of terminal use (for example, the fill-in-the-blanks mode). However, there must be at least one language whose statements are expressible, per some well-defined syntax, as character strings and whose ability to support all the following is comprehensible: data definition, view definition, data manipulation (interactive and by program), integrity constraints, authorization, and transaction boundaries (begin, commit, and rollback).
View Updating Rule: All views that are theoretically updatable are also updatable by the system.
High-level Insert, Update, and Delete: The capability of handling a base relation or a derived relation as a single operand applies not only to the retrieval of data but also to the insertion, update and deletion of data.
Physical Data Independence: Application programs and terminal activities remain logically unimpaired whenever any changes are made in either storage representations or access methods.
Logical Data Independence: Application programs and terminal activities remain logically unimpaired when information preserving changes of any kind that theoretically permit unimpairment are made to the base tables.
Integrity Independence: Integrity constraints specific to a particular relational database must be definable in the relational data sublanguage and storable in the catalog, not in the application programs.
Distribution Independence: A relational DBMS has distribution independence. Distribution independence implies that users should not have to be aware of whether a database is distributed.
Non-subversion Rule: If a relational system has a low-level (single-record-at-a-time) language, that low level cannot be used to subvert or bypass the integrity rules and constraints expressed in the higher-level relational language (multiple-records-at-a-time).
These rules have played a significant role in shaping the design and implementation of relational databases over the past few decades. They have been used as a benchmark to evaluate the quality of database management systems and to ensure that the systems adhere to the fundamental principles of the relational model.
Q3 (a) What is Data Mining? Explain all the techniques of data mining in detail. (7.5)
Data mining is the process of discovering hidden patterns and relationships in large datasets. The purpose of data mining is to extract useful information from data and use it to make predictions or decisions. There are several techniques of data mining that can be used to achieve this goal:
Classification: Classification is a technique that is used to predict the class label of a new data instance based on its characteristics. It is used to identify which category a new instance belongs to by analyzing the attributes of previously classified data.
Clustering: Clustering is a technique that is used to group similar data instances together. It is used to find natural groupings in data without prior knowledge of the class labels.
Association Rule Mining: Association rule mining is a technique used to discover interesting relationships between items in a dataset. It is used to identify which items frequently occur together in a dataset.
Anomaly Detection: Anomaly detection is a technique used to identify unusual patterns in data that do not conform to expected behavior. It is used to identify rare or unusual events in a dataset.
Regression: Regression is a technique used to model the relationship between two variables. It is used to predict the value of one variable based on the value of another variable.
Sequential Pattern Mining: Sequential pattern mining is a technique used to discover patterns in sequential data. It is used to identify patterns that occur over time, such as in stock market data or website usage patterns.
Text Mining: Text mining is a technique used to extract useful information from unstructured text data. It is used to analyze large amounts of text data, such as social media posts, news articles, or customer feedback.
(b) What are HYPERCUBE? How do they apply in OLAP? (5)
In OLAP (Online Analytical Processing), a hypercube is a multidimensional array of data that represents the data cube. A data cube is a data structure that is used to store and analyze data from multiple dimensions. A hypercube is an extension of a cube that allows for the analysis of data from more than three dimensions.
In OLAP, a hypercube is used to represent the data cube and to perform complex queries on the data. A hypercube allows for the analysis of data from multiple dimensions, such as time, geography, and product, and allows users to drill down into the data to see more detailed information. Hypercubes are also used to support data mining and other analytical techniques. They provide a powerful tool for analyzing large datasets and making informed business decisions based on the insights gained from the analysis.
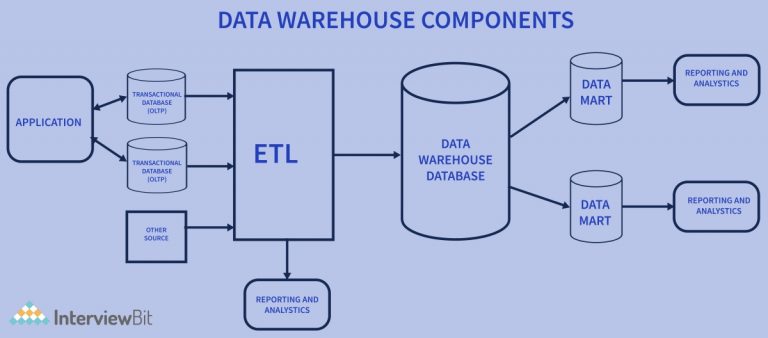
Q4 (a) What are the basic components of data warehouse explain with the help of diagram? (6.5)
The basic components of a data warehouse are:
Data Sources: Data sources are the various systems and applications that provide data to the data warehouse. These sources can be internal or external, structured or unstructured.
ETL (Extract, Transform, Load) Processes: The ETL process is used to extract data from various sources, transform it into a common format, and load it into the data warehouse.
Data Warehouse Database: This is where the structured data is stored in a centralized repository. It typically consists of one or more large tables with millions of rows of data.
Metadata: Metadata is data about the data in the data warehouse. It includes information such as data lineage, data definitions, data relationships, and data quality.
OLAP (Online Analytical Processing) Tools: OLAP tools are used to extract insights and trends from the data warehouse. These tools provide interactive analysis of data, allowing users to drill down, slice, dice and aggregate data to discover insights.
Here's a diagram that shows the components of a data warehouse:
(b) Explain Dimension Table in wide, the fact table is Deep. What is Fact less Fact Table? (6)
(b) A dimension table is a table in a data warehouse that contains information about the various attributes or dimensions of a particular entity. For example, a dimension table for a sales data warehouse might include dimensions such as date, product, location, and customer.
The fact table, on the other hand, is the central table in the data warehouse that contains the measures or facts that are being analyzed, such as sales revenue, units sold, or profit.
A factless fact table is a fact table that does not contain any measures. Instead, it captures the relationships between dimensions. Factless fact tables are typically used in scenarios where the relationship between dimensions is important, but there are no numerical facts associated with them. For example, a factless fact table could be used to capture the relationships between a customer and a product they viewed, but did not purchase.
Q5 What are the various ways by which corporate can provide strategic information for decision making? Explain each in detail?
Ways in which corporations can provide strategic information for decision making:
Business Intelligence: The use of data analysis tools and techniques to extract insights from data to aid in decision making.
Dashboards and Scorecards: Visual representations of key performance indicators (KPIs) that help executives and managers monitor and track progress towards strategic goals.
Data Warehousing: The process of collecting, storing, and managing large amounts of data from different sources to support decision making.
Predictive Analytics: The use of statistical and machine learning algorithms to analyze historical data and predict future outcomes.
Simulation and Modeling: The creation of models and simulations to test different scenarios and help identify the best course of action.
Q6 (a) Explain the applications of data mining for Telecommunication industry?
Applications of data mining for Telecommunication industry:
Customer Segmentation: The use of data mining techniques to group customers based on their behavior, demographics, and preferences.
Churn Prediction: The use of data mining to identify customers who are likely to leave the company and take preemptive action to retain them.
Fraud Detection: The use of data mining to detect fraudulent activities such as unauthorized usage or billing.
Network Optimization: The use of data mining to optimize the network infrastructure to improve performance and reduce costs.
Call Detail Record (CDR) Analysis: The analysis of CDR data to identify calling patterns and trends, and improve network planning and resource allocation.
6 (b) Explain with diagram, Knowledge discovery phase?
Data Selection: The process of selecting the relevant data from various sources.
Data Preprocessing: The process of cleaning, transforming, and integrating the data to prepare it for analysis.
Data Reduction: The process of reducing the amount of data to be analyzed by selecting a representative subset or by aggregating the data.
Data Mining: The process of applying various data mining techniques to extract meaningful patterns and insights from the data.
Pattern Evaluation: The process of evaluating the patterns and insights discovered to ensure that they are meaningful and useful.
Knowledge Representation: The process of representing the knowledge in a format that can be easily understood and used by decision makers.
Knowledge Utilization: The process of using the knowledge to improve decision making and achieve the desired objectives.
Metadata refers to the data that provides information about other data. It includes information like the structure, format, quality, location, and meaning of data. It is important because it enables efficient management and use of data and facilitates understanding of the relationships between different data elements.
Multidimensional data refers to data that is organized in a way that enables efficient analysis of relationships between different variables. It is used in OLAP systems and involves organizing data into dimensions, measures, and hierarchies. Metadata is essential in multidimensional data as it helps users to understand the structure and meaning of the data and enables efficient navigation and analysis of the data.
The different types of metadata include descriptive metadata (information about the structure and content of data), administrative metadata (information about data ownership, access rights, and usage), and technical metadata (information about data format, storage, and processing).
Q7 (b) Differentiate between operational system and information system. (5)
Operational systems are designed to support the day-to-day operations of an organization. They are transaction-oriented and designed to capture and process large volumes of operational data in real-time. They are optimized for data entry and retrieval and support the needs of individual departments or business units.
Information systems, on the other hand, are designed to provide decision-makers with timely and accurate information for decision-making. They are analytical in nature and are used to process and analyze data from multiple sources to provide insights and support decision-making at a strategic level. They are optimized for reporting, analysis, and data visualization and are designed to support the needs of the entire organization.
| Operational System | Information System |
|---|---|
| Designed to execute day-to-day transactions. | Designed to support decision-making activities. |
| Provides real-time transaction processing. | Provides historical and summarized data analysis. |
| Typically deals with structured data. | Deals with structured, semi-structured and unstructured data. |
| Data is transactional and current. | Data is integrated, subject-oriented and time-variant. |
| Database design is normalized. | Database design is denormalized for faster queries. |
Q8. Explain the following in detail:-
(a) MOLAP
(b) ROLAP
(c) Neural Networks
(d) Genetic Algorithms
(e) Information Package
(a) MOLAP (Multidimensional Online Analytical Processing) is a method of storing data in a multidimensional database, which enables faster querying and analysis of data. MOLAP uses a specialized storage engine and precomputes aggregations to improve performance. It provides fast query response times but can be limited by the amount of data it can handle.
(b) ROLAP (Relational Online Analytical Processing) is a method of storing data in a relational database that is optimized for reporting and analysis. It uses SQL queries to access data and provides flexibility in handling complex relationships between data. ROLAP provides scalable and flexible data models but can be slower than MOLAP when querying large amounts of data.
(c) Neural Networks are a type of machine learning algorithm that is modeled after the structure of the human brain. They are used for pattern recognition, classification, and prediction. They learn from examples and can be trained to identify patterns in data. Neural networks can be used for various applications such as image recognition, speech recognition, and financial forecasting.
(d) Genetic Algorithms are a type of optimization algorithm that is modeled after the principles of evolution. They are used to find the best solution to a problem by iteratively generating and selecting candidates for optimization. They simulate the process of natural selection by selecting the most promising candidates and generating new ones based on them. Genetic algorithms can be used for various applications such as financial forecasting, engineering optimization, and scheduling problems.
(e) An Information Package is a set of metadata and data that is used to define a unit of information in a data warehouse. It contains information about the data source, transformation rules, and the data itself. Information packages are used to define data marts, which are subsets of the data warehouse that are optimized for specific business functions. They enable easy access to data and support fast querying and analysis.



Comments
Post a Comment