Machine Learning End Term 2020
Machine Learning End Term Examination 2020 (ETCS 402)
Q1. All questions are compulsory.(2.5x10=25)
(a) Explain the goals of machine learning
The goals of machine learning are to enable computers to learn from data and make predictions or decisions without being explicitly programmed. The main goals include:
Prediction: Creating models that can accurately predict future outcomes or behaviors based on historical data.
Classification: Grouping data into categories or classes based on their features.
Clustering: Identifying patterns or similarities in data to group them into clusters.
Anomaly detection: Identifying unusual or abnormal data points that deviate from the norm.
Optimization: Finding the best solution or set of parameters that optimize a specific objective or performance metric.
(b) What is bagging?
Bagging, short for Bootstrap Aggregating, is a technique used in machine learning to improve the performance and stability of models. It involves creating multiple subsets of the training data by randomly sampling with replacement. Each subset is used to train a separate model, and the final prediction is obtained by aggregating the predictions from all models (e.g., averaging for regression or voting for classification). Bagging helps to reduce the impact of outliers and noise in the training data and can improve the overall accuracy and robustness of the model.
(c) What is the role of a kernel in Support Vector Machine classifier?
In Support Vector Machine (SVM) classifiers, a kernel is a function that transforms the input data into a higher-dimensional feature space. The role of the kernel is to enable the SVM to find a hyperplane that effectively separates the data points into different classes. It allows the SVM to handle non-linearly separable data by mapping it to a higher-dimensional space where it becomes linearly separable. The commonly used kernel functions include linear, polynomial, radial basis function (RBF), and sigmoid kernels
(d) What is boosting?
Boosting is a machine learning technique that combines multiple weak or simple models (often referred to as weak learners) to create a strong predictive model. The weak models are trained sequentially, and each subsequent model focuses on the samples that the previous models struggled with. The final prediction is made by aggregating the predictions of all weak models, typically using a weighted voting approach. Boosting helps to improve the accuracy and generalization ability of the model by reducing bias and variance.
(e) What is a perception? Explain in brief.
Perceptron is a simple algorithm used for binary classification tasks. It is based on the concept of a neural network with a single layer of artificial neurons called perceptrons. The algorithm iteratively adjusts the weights and biases of the perceptrons to find the decision boundary that separates the two classes. It learns from labeled training data, where the perceptron updates its parameters based on the errors made in classification. The process continues until the algorithm converges or reaches a predefined stopping criterion. The perceptron algorithm is a building block for more advanced neural network models.
(f) Explain KNN classifier
KNN (K-Nearest Neighbors) classifier is a type of instance-based learning algorithm used for classification tasks. It classifies a new data point based on the majority vote of its K nearest neighbors in the training set. The distance metric, such as Euclidean distance, is used to measure the similarity between data points. KNN is a non-parametric algorithm, meaning it does not make any assumptions about the underlying data distribution. It can handle both binary and multi-class classification problems and is relatively simple to implement.
(g) What is Linear Quadratic Regulation?
Linear Quadratic Regulation (LQR) is a mathematical technique used in control systems to design controllers for systems with predictable behavior. It aims to find the optimal control strategy that minimizes a quadratic cost function while keeping the system stable. LQR considers the dynamics of the system, the control inputs, and the desired performance criteria to compute the optimal control actions. It is widely used in robotics, aerospace, and other engineering fields.
(h) What is Direct Policy Search?
Direct Policy Search is a reinforcement learning approach where the policy, or the mapping from states to actions, is directly learned without explicitly modeling the environment. It explores the policy space to find the one that maximizes the expected cumulative reward. This approach is particularly useful in complex and high-dimensional environments where modeling the environment explicitly is difficult or impractical. Direct Policy Search methods include evolutionary algorithms, stochastic gradient ascent, and policy gradient algorithms.
(i) What is logistic regression?
Logistic regression is a supervised learning algorithm used for binary classification tasks. It models the relationship between the input features and the binary output variable using the logistic function (also known as the sigmoid function). Logistic regression estimates the probability of the input belonging to a specific class, and based on a predefined threshold, it assigns the most likely class label. It is a linear model that applies a transformation to the linear regression output to obtain a value between 0 and 1, representing the probability.
(j) What is the difference between supervised and unsupervised learning?
The main difference between supervised and unsupervised learning lies in the availability of labeled data. In supervised learning, the training data consists of input features and corresponding target labels, and the goal is to learn a mapping between the inputs and outputs. The model learns from the labeled examples and can make predictions on new, unseen data. In unsupervised learning, the training data does not have any labels, and the model must find patterns, structures, or relationships in the data without explicit guidance. It is mainly used for exploratory analysis, clustering, dimensionality reduction, and anomaly detection.
Q2 a) Explain the generative probabilistic classification.
Generative probabilistic classification is a machine learning approach that models the joint probability distribution of the input features and the target labels. It aims to estimate the conditional probability of a particular class given the input features using Bayes' theorem. By modeling the entire distribution, generative models can generate new samples and perform tasks such as density estimation. Examples of generative models include Naive Bayes, Gaussian Mixture Models, and Hidden Markov Models.
b) Explain the over fitting in machine learning. Explain applications of machine learning.
verfitting occurs in machine learning when a model becomes too complex and starts to fit the training data too closely, resulting in poor generalization to new, unseen data. It happens when the model captures noise or irrelevant patterns from the training data, leading to reduced performance on test data. Overfitting can be mitigated by using techniques such as regularization, cross-validation, and early stopping.
Machine learning has numerous applications across various domains. Some common applications include:
Image and object recognition: Machine learning algorithms can classify and detect objects in images or videos, enabling applications such as facial recognition and autonomous driving.
Natural language processing: Machine learning models can understand and process human language, enabling applications such as sentiment analysis, chatbots, and language translation.
Recommender systems: Machine learning algorithms can analyze user preferences and provide personalized recommendations, commonly seen in platforms like Netflix and Amazon.
Fraud detection: Machine learning models can identify fraudulent transactions by learning patterns from historical data and detecting anomalies.
Medical diagnosis: Machine learning algorithms can analyze medical data to assist in diagnosing diseases and predicting patient outcomes.
c) How approximate functions works? What is value function approximation? Can neural network approximate any function? Explain.
Approximate functions refer to the process of representing complex mathematical functions using simpler and computationally efficient approximations. Value function approximation is a technique used in reinforcement learning to estimate the value function, which represents the expected future rewards for different states or state-action pairs. Instead of storing values for each possible state or state-action pair, value function approximation uses a function approximator to generalize across similar states or actions.
Neural networks are a powerful tool for function approximation, as they can learn complex mappings between inputs and outputs. With a sufficient number of hidden layers and neurons, neural networks have the capability to approximate any continuous function to a desired level of accuracy, as shown by the Universal Approximation Theorem. However, it is important to note that training a neural network requires sufficient data, appropriate architecture design, and careful tuning of hyperparameters to achieve good approximation performance.
Q3 a) Explain the model of learning in detail.
The model of learning refers to the framework or approach used to build a machine learning system. It involves defining the problem, selecting an appropriate algorithm or model, and training it on labeled data to make predictions or extract meaningful insights. The model of learning typically includes the following steps:
Problem definition: Clearly defining the task at hand, whether it's classification, regression, clustering, or other types of learning problems.
Data collection and preprocessing: Gathering relevant data and preparing it for analysis, which may involve cleaning, transforming, and normalizing the data.
Feature selection and engineering: Identifying the most relevant features that will be used by the model to make predictions. This step may also involve creating new features from the existing ones.
Model selection: Choosing an appropriate algorithm or model that is suitable for the problem and the available data. This may include decision trees, support vector machines, neural networks, or other models.
Training the model: Using the labeled data to train the model by adjusting its parameters or weights to minimize the error or maximize the performance metric.
Model evaluation: Assessing the performance of the trained model using evaluation metrics such as accuracy, precision, recall, or others. This step helps to gauge the effectiveness of the model and identify areas for improvement.
Model deployment and testing: Once the model is trained and evaluated, it can be deployed to make predictions on new, unseen data and tested for its real-world performance.
b) Perform the KNN Classification on following dataset and predict the class of X(P1=3,P2=7). Where k=3.
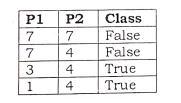
- Begin with the entire dataset as the root node.
- Select a feature that best splits the dataset based on certain criteria (e.g., information gain, Gini impurity).
- Create a branch for each possible value of the selected feature.
- Recursively repeat steps 2 and 3 for each subset of data in the branches until a stopping criterion is met (e.g., reaching a maximum depth, minimum number of samples).
- Assign the majority class of the training samples in each leaf node as the predicted class.
- P(A|B) represents the posterior probability of event A given event B.
- P(B|A) is the likelihood, which is the probability of observing event B given event A.
- P(A) is the prior probability of event A.
- P(B) is the probability of observing event B.

- Classification is a supervised learning task where the goal is to assign predefined labels or categories to input data based on their features.
- The process involves training a model on labeled training data to learn the patterns and relationships between the features and the labels.
- The trained model can then be used to predict the labels of unseen data.
- Clustering is an unsupervised learning task where the goal is to group similar data points together based on their intrinsic characteristics.
- The process involves finding the underlying structure or patterns in the data without any predefined labels.
- Clustering algorithms group data points based on their similarity or distance metrics, aiming to maximize the similarity within clusters and minimize the similarity between clusters.
- Choose the value of K, which represents the number of clusters we want to create.
- Randomly initialize K cluster centroids.
- Assign each data point to the nearest centroid based on their distance.
- Recalculate the centroids by taking the mean of all data points assigned to each cluster.
- Repeat steps 3 and 4 until convergence or a maximum number of iterations.
- Generative models learn the joint probability distribution of the input features and the corresponding labels.
- They aim to model the underlying process that generates the data and can generate new samples.
- Given the input features, a generative model can estimate the likelihood of different labels.
- Examples of generative models include Naive Bayes, Hidden Markov Models, and Gaussian Mixture Models.
- Discriminative models directly learn the decision boundary between different classes or labels.
- They focus on learning the conditional probability distribution of the labels given the input features.
- Discriminative models aim to find the most optimal decision boundary that separates different classes.
- Examples of discriminative models include Logistic Regression, Support Vector Machines, and Neural Networks.
- Feature Selection: This approach involves selecting a subset of the original features based on their relevance to the target variable. The selected features are retained, while the irrelevant or redundant ones are discarded. This helps in reducing the dimensionality of the data and eliminating noise or irrelevant information.
- Feature Extraction: This approach aims to transform the original high-dimensional data into a lower-dimensional space by creating new features that capture the most important information. Techniques such as Principal Component Analysis (PCA) and Singular Value Decomposition (SVD) are commonly used for feature extraction.
- Observation: The agent observes the current state of the environment.
- Action: Based on the observed state, the agent selects an action to perform.
- Feedback: The agent receives feedback from the environment in the form of a reward or penalty.
- Update: The agent updates its knowledge or policy based on the received feedback.
- Repeat: The agent continues the loop by observing, taking actions, and updating until it learns the optimal policy.

- Assign initial weights: Each instance in the training set is assigned an equal weight.
- Train weak classifiers: A series of weak classifiers are trained on the data.
- Evaluate weak classifiers: The performance of each weak classifier is evaluated on the training set.
- Update instance weights: Instances that are misclassified are assigned higher weights, while correctly classified instances are assigned lower weights.
- Combine weak classifiers: The weak classifiers are combined into a strong classifier based on their individual performance and instance weights.
- Repeat: Steps 3-5 are repeated for a specified number of iterations or until a desired level of accuracy is achieved.
- PCA is a linear transformation technique that aims to find a new set of orthogonal axes (principal components) that captures the maximum variance in the data.
- It projects the data onto these components, where the first component explains the most variance, the second component explains the second most variance, and so on.
- PCA is commonly used for feature extraction, data compression, and data visualization.
- It does not assume any specific distribution of the data.
- ICA is a statistical technique that aims to separate a set of mixed signals into their underlying independent components.
- It assumes that the observed data is a linear combination of independent source signals, and it seeks to estimate the original sources.
- ICA is useful for tasks such as blind source separation, speech recognition, and image denoising.
- It relies on the statistical independence assumption and assumes that the sources have a non-Gaussian distribution.
- Value iteration is an iterative algorithm that calculates the optimal value function by repeatedly updating the values of states.
- It starts with an initial estimate of the value function and iteratively improves it until convergence.
- In each iteration, the algorithm updates the value of each state by considering all possible actions and their corresponding expected returns.
- Value iteration converges to the optimal value function and policy.
- Policy iteration is an iterative algorithm that alternates between policy evaluation and policy improvement steps.
- It starts with an initial policy and iteratively improves it by evaluating and updating the value function.
- In the policy evaluation step, the algorithm calculates the value function for the current policy.
- In the policy improvement step, the algorithm updates the policy by selecting the action that maximizes the expected return.
- Policy iteration converges to the optimal policy and value function.
- LQR is a control strategy for continuous-time linear systems with quadratic cost functions.
- It aims to find an optimal control policy that minimizes a quadratic cost function, considering the system dynamics and control constraints.
- LQR uses the dynamic programming principle and the Riccati equation to compute the optimal control gains.
- LQG is an extension of the LQR framework that incorporates uncertainty in the system dynamics and sensor measurements.
- It considers a linear system with Gaussian noise in the dynamics and measurements.
- LQG combines the LQR control policy with a Kalman filter that estimates the system state based on noisy measurements.
- The LQG controller adjusts the control action based on the estimated state to optimize the system performance.



Comments
Post a Comment